
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 영상처리
- 백준
- python
- c
- OpenCV
- 회귀
- 운영체제
- 백준알고리즘
- CV
- Computer Vision
- Windows 10
- 학습
- 시스템프로그래밍
- TensorFlow
- linux
- 리눅스
- C++
- 딥러닝
- C언어
- Windows10
- 공부
- 프로그래밍
- error
- 텐서플로우
- 알고리즘
- 턱걸이
- 코딩
- 프로세스
- shell
- 쉘
Archives
- Today
- Total
줘이리의 인생적기
[tensorflow 22] Fashion MNIST02 본문
728x90
[tensorflow 19]에서 Fashion MNIST를 Dense 레이어를 사용하여 분류하였습니다.
이번에는 새롭게 공부한 컨폴루션, 풀링 레이어를 이용하여 분류해보겠습니다.
[tensorflow 19]와 동일하게 정규화를 진행하고, 컨볼루션 연산을 진행하겠습니다.
Conv2D 연산을 하기 위해서는 채널을 가진 데이터의 형태로 Shape를 변경해야 합니다.
Shape 변경 후 모델 구성을 해보도록 하겠습니다.
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_X, train_Y), (test_X, test_Y) = fashion_mnist.load_data()
train_X = train_X / 255.0
test_X = test_X / 255.0
print("reshape 이전 => ", train_X.shape, test_X.shape)
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
print("reshape 이후 => ", train_X.shape, test_X.shape)
Fashion MNIST는 흑백 이미지라 1개의 채널을 갖기 때문에 가장 뒤쪽 1개의 채널 차원을 추가하였습니다.
이제 모델을 생성하고, 학습을 진행해보도록 하겠습니다.
3개의 Conv2D 레이어를 사용하였고, 높이28 너비28 채널1개의 input_size를 지정하였습니다.
필터의 수는 2배씩 증가하도록 16, 32, 64를 지정하였습니다.
그 이후, Flatten 레이어로 2차원 데이터를 1차원 정렬 후 Dense 레이어를 사용하여 classifier를 만들었습니다.
(Pooling과 Dropout은 비교를 위해 다음 포스팅에서 적용시켜보겠습니다.)
import tensorflow as tf
import matplotlib.pyplot as plt
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_X, train_Y), (test_X, test_Y) = fashion_mnist.load_data()
train_X = train_X / 255.0
test_X = test_X / 255.0
# print("reshape 이전 => ", train_X.shape, test_X.shape)
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
# print("reshape 이후 => ", train_X.shape, test_X.shape)
#모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(input_shape=(28,28,1), kernel_size=(3,3), filters=16),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=32),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dense(units=10, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_X, train_Y, epochs=25, validation_split=0.25)
#loss 시각화
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy')
plt.xlabel('Epoch')
plt.ylim(0.7, 1)
plt.legend()
plt.show()
model.evaluate(test_X, test_Y, verbose=0)
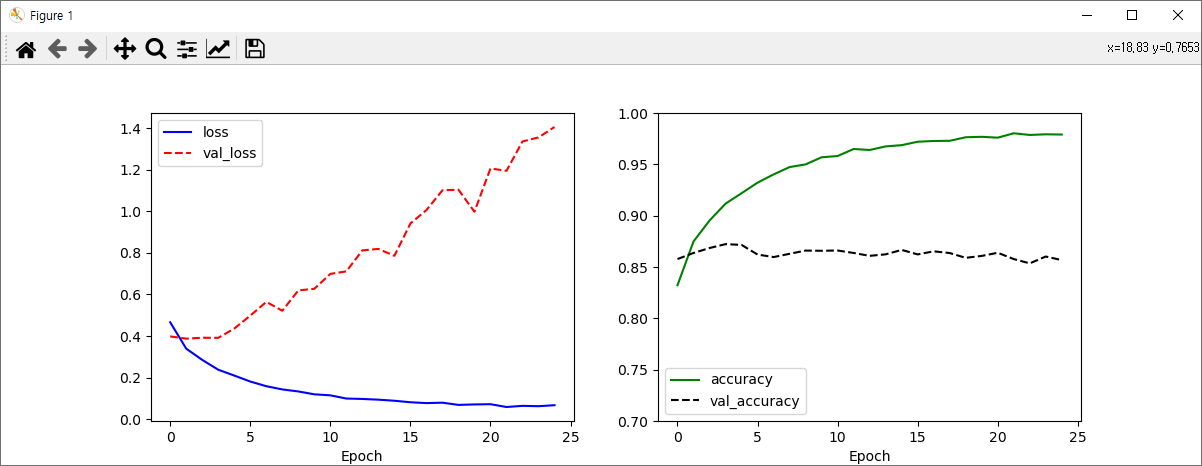


테스트 결과는 85.5퍼센트가 나왔습니다.
생각보다 그렇게 좋지 않은 결과입니다.
Pooling 레이어와 Dropout 레이어를 추가하게 된다면 어떻게 될까요?
'공부 > tensorflow' 카테고리의 다른 글
| [tensorflow 24] Fashion MNIST04 (0) | 2021.05.27 |
|---|---|
| [tensorflow 23] Fashion MNIST03 (0) | 2021.05.26 |
| [tensorflow 21] 레이어 (0) | 2021.05.24 |
| [tensorflow 20] CNN - 특징 추출 (0) | 2021.05.21 |
| [tensorflow 19] Fashion MNIST01 (0) | 2021.05.20 |
'공부/tensorflow' Related Articles
more



