
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- shell
- 쉘
- 시스템프로그래밍
- C++
- TensorFlow
- 학습
- 회귀
- 영상처리
- OpenCV
- error
- 턱걸이
- 공부
- 운영체제
- 백준알고리즘
- python
- 알고리즘
- Computer Vision
- 딥러닝
- Windows10
- 백준
- 텐서플로우
- C언어
- CV
- 프로세스
- 프로그래밍
- c
- 코딩
- Windows 10
- linux
- 리눅스
Archives
- Today
- Total
줘이리의 인생적기
[tensorflow 15] 보스턴 주택 가격 예측 네트워크02 본문
728x90
앞선 포스팅에서 사용했었던 Sequantial 모델을 사용하도록 하겠습니다.
4개의 Dense 레이어, relu, Adam, mse를 사용하겠습니다.
from tensorflow.keras.datasets import boston_housing
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#데이터셋 가져오기
(train_X, train_Y), (test_X, test_Y) = boston_housing.load_data()
###########정규화 (Standardization) #############
# X 값 Standardization
X_mean = train_X.mean(axis=0)
X_std = train_X.std(axis=0)
train_X = train_X - X_mean
train_X = train_X / X_std
test_X = test_X - X_mean
test_X = test_X / X_std
# Y 값 Standardization
Y_mean = train_Y.mean(axis=0)
Y_std = train_Y.std(axis=0)
train_Y = train_Y - Y_mean
train_Y = train_Y / Y_std
test_Y = test_Y - Y_mean
test_Y = test_Y / Y_std
# Sequential 모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=52, activation='relu', input_shape=(13, )),
tf.keras.layers.Dense(units=39, activation='relu'),
tf.keras.layers.Dense(units=26, activation='relu'),
tf.keras.layers.Dense(units=1)
])
# compile
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.05), loss='mse')
history = model.fit(train_X, train_Y, epochs=30, batch_size=32, validation_split=0.2)
############## loss와 validation loss 값 그래프 #############
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
################ 실제 vs 예측 가격 비교 ##############
pred_Y = model.predict(test_X)
plt.figure(figsize=(5, 5))
plt.plot(test_Y, pred_Y, 'b.')
plt.axis([min(test_Y), max(test_Y), min(test_Y), max(test_Y)])
# y=x 대각선
plt.plot([min(test_Y), max(test_Y)], [min(test_Y), max(test_Y)], ls="-", c=".5")
plt.xlabel('test_Y')
plt.ylabel('pred_Y')
plt.show()
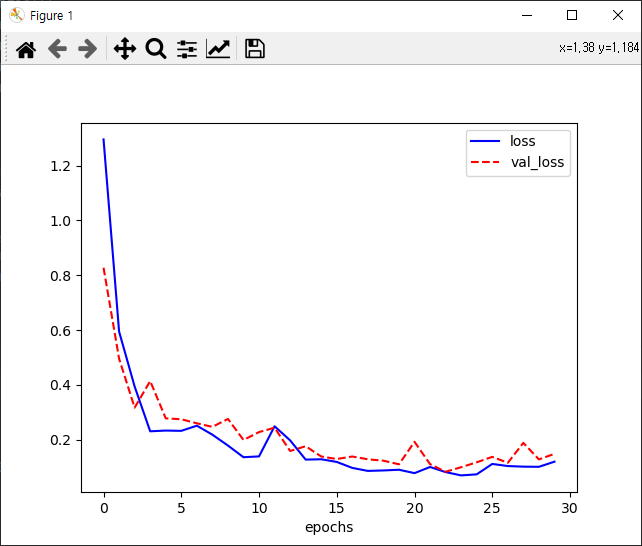
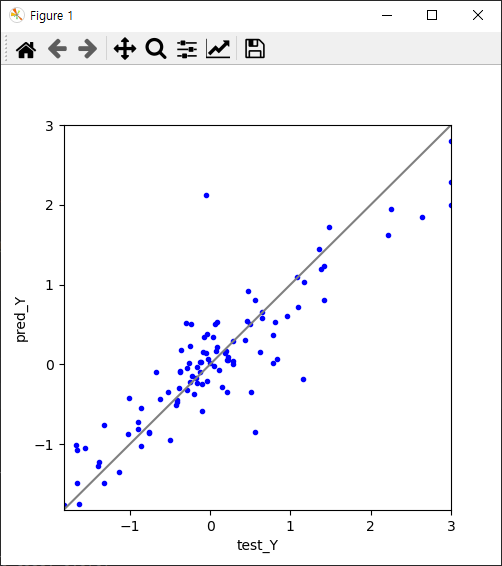
왼쪽 사진부터 보면 loss그래프를 보면 잘 떨어지다가 조금씩 요동칩니다.
오른쪽 사진은 실제 가격과 얼추 비슷하나 어느정도 차이가 있네요.
validation loss값이 0.13~0.14정도에서 왔다 갔다하네요.
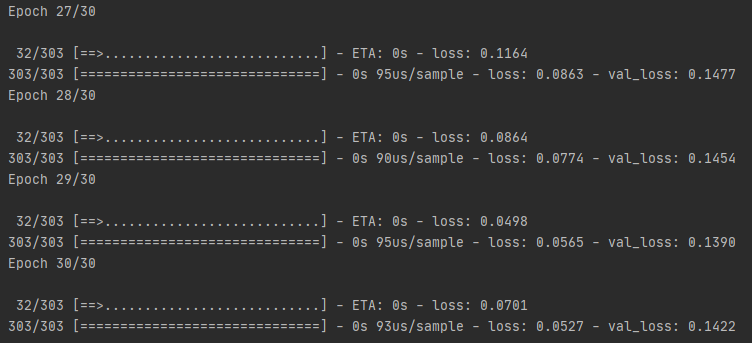
eva = model.evaluate(test_X, test_Y)
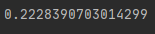
print(eva)평가를 위해 코드 마지막에 위 코드를 삽입했을 때 테스트데이터의 손실이 0.222가 나왔습니다.
validation loss값이 높아지지 않기 위해서는 어떻게 하면 좋을까요?
네트워크가 train data에 과적합 되지 않도록 중간에 학습을 끊어주어야 합니다.
callbacks 인수를 사용해 validation loss값이 지정횟수만큼 최고 기록을 갱신하지 않을 때 끊어주도록 하겠습니다.
from tensorflow.keras.datasets import boston_housing
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#데이터셋 가져오기
(train_X, train_Y), (test_X, test_Y) = boston_housing.load_data()
###########정규화 (Standardization) #############
# X 값 Standardization
X_mean = train_X.mean(axis=0)
X_std = train_X.std(axis=0)
train_X = train_X - X_mean
train_X = train_X / X_std
test_X = test_X - X_mean
test_X = test_X / X_std
# Y 값 Standardization
Y_mean = train_Y.mean(axis=0)
Y_std = train_Y.std(axis=0)
train_Y = train_Y - Y_mean
train_Y = train_Y / Y_std
test_Y = test_Y - Y_mean
test_Y = test_Y / Y_std
# Sequential 모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=52, activation='relu', input_shape=(13, )),
tf.keras.layers.Dense(units=39, activation='relu'),
tf.keras.layers.Dense(units=26, activation='relu'),
tf.keras.layers.Dense(units=1)
])
# compile
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.05), loss='mse')
history = model.fit(train_X, train_Y, epochs=30, batch_size=32, validation_split=0.2, callbacks=[tf.keras.callbacks.EarlyStopping(patience=6, monitor='val_loss')])
############## loss와 validation loss 값 그래프 #############
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
################ 실제 vs 예측 가격 비교 ##############
pred_Y = model.predict(test_X)
plt.figure(figsize=(5, 5))
plt.plot(test_Y, pred_Y, 'b.')
plt.axis([min(test_Y), max(test_Y), min(test_Y), max(test_Y)])
# y=x 대각선
plt.plot([min(test_Y), max(test_Y)], [min(test_Y), max(test_Y)], ls="-", c=".5")
plt.xlabel('test_Y')
plt.ylabel('pred_Y')
plt.show()EarlyStopping으로 6번안에 새로운 값을 갱신 안하면 스탑하도록 설정했습니다.
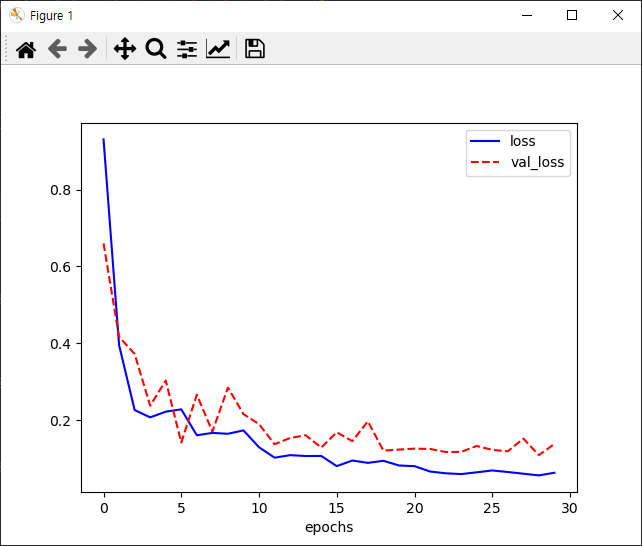
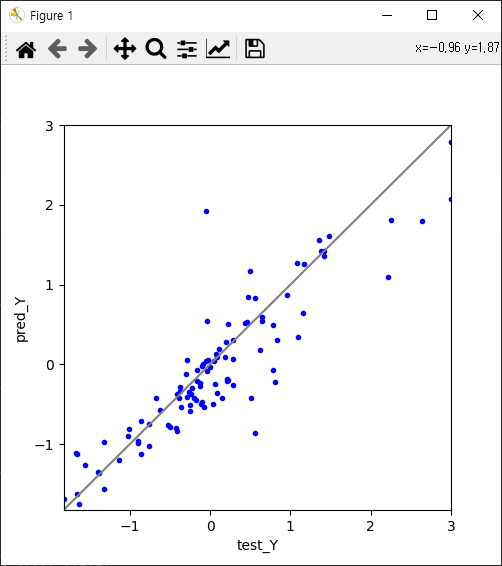
실제 가격과 예측가격을 비교한 그래프(오른쪽)사진을 보니 운좋게 조금 더 잘 예측한 것 같네요
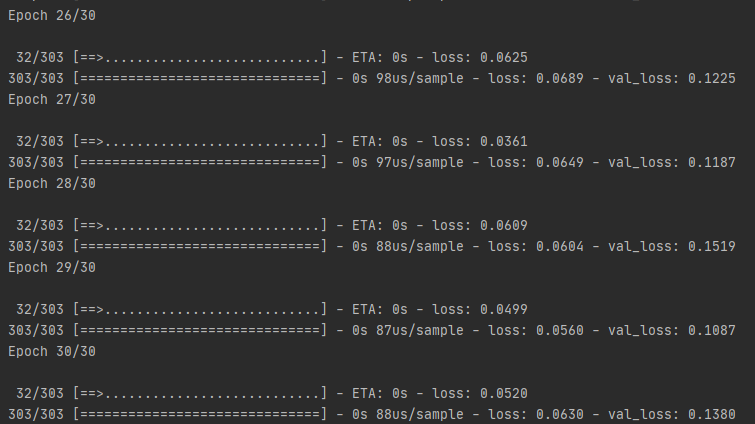
epoch 30번 동안 새로운 갱신을 못했군요
평가를 진행해보겠습니다.
eva = model.evaluate(test_X, test_Y)
print(eva)
사실 바뀐 것은 없는데 손실이 0.22에서 0.19로 떨어졌네요
갱신을 하지 못해 학습을 멈추지 못했지만 이렇게 callbacks인수를 활용하면 과적합을 막을 수 있습니다.
'공부 > tensorflow' 카테고리의 다른 글
| [tensorflow 17] 이항 분류02 (0) | 2021.05.18 |
|---|---|
| [tensorflow 16] 이항 분류01 (0) | 2021.05.17 |
| [tensorflow 14] 보스턴 주택 가격 예측 네트워크01 (0) | 2021.04.23 |
| [tensorflow 13] 딥러닝 네트워크 회귀 (0) | 2021.04.22 |
| [tensorflow 12] 다항회귀 (0) | 2021.04.21 |
'공부/tensorflow' Related Articles
more



