
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 백준
- 쉘
- 프로그래밍
- Windows 10
- 운영체제
- Computer Vision
- 백준알고리즘
- TensorFlow
- 시스템프로그래밍
- 턱걸이
- C언어
- 영상처리
- error
- 회귀
- Windows10
- 알고리즘
- OpenCV
- shell
- python
- 학습
- 프로세스
- c
- 공부
- 코딩
- 딥러닝
- linux
- 텐서플로우
- CV
- C++
- 리눅스
- Today
- Total
줘이리의 인생적기
[tensorflow 07] XOR 연산 뉴런 본문
결론부터 말하자면, 하나의 퍼셉트론으로는 간단한 XOR연산자도 만들어낼 수 없습니다.
(Marvin Minsky, Seymour Papert가 증명)
안 되는 XOR 네트워크를 만들어볼 텐데, 앞서 공부한 OR, AND 연산처럼 XOR 진리표부터 보겠습니다.

import tensorflow as tf
import math
import numpy as np
def sigmoid(x):
return 1 / (1 + math.exp(-x))
x = np.array([[1,1], [1,0], [0,1], [0,0]])
y = np.array([[0], [1], [1], [0]]) # 거짓 참 참 거짓
w = tf.random.normal([2], 0, 1)
b = tf.random.normal([1], 0, 1)
for i in range(2000):
error_sum = 0
for j in range(4):
output = sigmoid(np.sum(x[j]*w)+ 1*b)
error = y[j][0] - output
w = w + x[j] * 0.1 * error
b = b + 1 * 0.1 * error
error_sum += error
if i % 100 == 99:
print(i, "error_sum = ", error_sum)
에러의 합이 어느 순간부터 변하지 않습니다.
이를 해결하기 위해 3개의 퍼셉트론과 뉴런을 사용해보겠습니다.
import tensorflow as tf
import math
import numpy as np
x = np.array([[1,1], [1,0], [0,1], [0,0]])
y = np.array([[0], [1], [1], [0]])
model = tf.keras.Sequential([tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2,)), tf.keras.layers.Dense(units=1, activation='sigmoid')])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1), loss='mse')
model.summary()
tf.keras를 이용하였는데요.
6번째 줄부터 설명하겠습니다.
tf.keras.Sequential을 이용하여 순차적(sequential)으로 레이어(뉴런과 뉴런이 합쳐진 단위)를 일직선으로 배치하였습니다.

tf.keras.layers.Dense는 model에서 사용하는 레이어를 정의하는 명령어입니다.
Dense는 가장 기본적인 레이어이며, 입력과 출력 사이에 있는 모든 뉴런이 서로 연결되는 레이어입니다.
Dense 안에 units는 뉴런의 수를 정의합니다.
(많을수록 성능, 계산량, 메모리 차지량 증가)
activation은 활성화 함수입니다, 두 레이어 모두 sigmoid를 사용하였습니다.
input_shape는 Sequential 모델의 첫 번째 레이어에서만 정의하는데, 입력의 차원수를 나타냅니다.
코드에서 나타난 네트워크의 구조는 아래와 같습니다.

마지막 화살표를 제외하고 각각 4개와 2개의 화살표는 가중치를 나타냅니다.
하지만 콘솔 출력창에서 Param #을 보게 되면 첫 번째 레이어에서는 6개, 두 번째 레이어에서는 3개입니다.
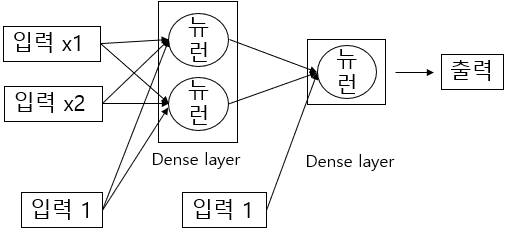
그 이유는 위 그림과 같이 기본적으로 편향을 포함하고 있어 6개, 3개로 표시되어집니다.
7번째 줄 코드는 model이 실제로 동작할 수 있도록 준비하는 명령어입니다.
원래는 복잡한 수학을 써야 하지만 미리 정의된 최적화 함수(optimizer)를 불러와 바로 사용할 수 있습니다.
SGD(Stochastic Gradient Descent)의 약자인 경사 하강법이며, 기울기가 낮은 쪽으로 가중치를 업데이트하겠다는 뜻입니다.
loss는 error와 비슷한 개념이며, 딥러닝은 이 손실(loss)을 줄이는 방향으로 학습합니다.
mse(Mean Squared Error)이며 평균 제곱 오차라는 뜻입니다.
코드 세 줄을 추가하여 XOR 네트워크 학습을 자세히 살펴보겠습니다.
import tensorflow as tf
import math
import numpy as np
x = np.array([[1,1], [1,0], [0,1], [0,0]])
y = np.array([[0], [1], [1], [0]])
model = tf.keras.Sequential([tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2,)), tf.keras.layers.Dense(units=1, activation='sigmoid')])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.3), loss='mse')
model.summary()
history = model.fit(x, y, epochs=2000, batch_size=1)
for weight in model.weights:
print(weight)

model.fit() 함수는 에포크(epoches)에 지정된 횟수만큼 학습시킵니다.
batch_size는 한 번에 학습시키는 데이터의 수를 뜻합니다.
model.weights에는 가중치 정보가 있습니다.
입력과 레이어, 레이어와 레이어 사의의 뉴런을 연결하는 가중치는 kernel, 편향과 연결된 가중치는 bias로 표시됩니다.

결괏값을 네트워크 구조에 입력해보았는데 가중치들이 한눈에 잘 들어오지 않습니다.
뉴런과 레이어가 많아지면 문제는 더욱 커지겠죠.
네트워크의 학습 상황을 잘 파악할 수 있는 방법이 필요해 보이네요.
'공부 > tensorflow' 카테고리의 다른 글
| [tensorflow 09] XOR 네트워크 시각화 (0) | 2021.04.13 |
|---|---|
| [tensorflow 08] matplotlib.pyplot 시각화 (0) | 2021.04.12 |
| [tensorflow 06] OR 연산 뉴런 (0) | 2021.04.08 |
| [tensorflow 05] AND 연산 뉴런 (0) | 2021.04.07 |
| [tensorflow 04] 뉴런02 - 뉴런 학습 (0) | 2021.04.06 |



